Programmation:C:Memoire
Sommaire
Introduction
La gestion de la mémoire en C est un point de passage obligatoire dans tout programme autre que Hello World. Dans ce cours, nous allons explorer les bases de manipulation des pointeurs, les différentes sortes d'allocation mémoire (statique, pile et tas), le fonctionnement de malloc(3) et enfin nous explorerons d'autre méthode de gestion de la mémoire.
Syntaxe des Pointeurs
La syntaxe des pointeurs est relativement simple. Il y a deux opérateurs de bases (référencement et déréférencement.) Les tableaux et les chaînes de caractères sont en réalité des pointeurs et les syntaxes qui leur sont spécifiques ne sont que des raccourcis sur la syntaxe des pointeurs.
Bases
Déréférencement
L'opération de base sur les pointeurs est le déréférencement qui consiste à suivre l'adresse du pointeur. La syntaxe est: *expr où expr est une expression de type pointeur. L'évaluation va dépendre du type (gauche ou droite) d'évaluation:
- Évaluation droite: l'expression est remplacée par la valeur se trouvant à l'adresse correspondante.
- Évaluation gauche: l'adresse est directement utilisée comme cible de l'affectation.
int *x; int a; /* allocation d'un espace pour x */ x = malloc(sizeof (int)); /* utilisation en valeur gauche */ *x = 42; /* utilisation en valeur droite */ a = 1 + *x;
Référencement
Le référencement est l'opération inverse de la précédante, elle consiste à récupérer l'adresse d'un conteneur. Par définition, on ne peut donc appliquer cette opération que sur une valeur gauche. L'opérateur de référencement ne s'applique donc qu'à des expressions pouvant être utilisées à gauche d'une affectation (variables, cases de tableaux, champ de structure ... )
La syntaxe est la suivante: &expr où expr est une valeur gauche (ou une expression s'évaluant en valeur gauche.)
/* utilisation "classique" */ int a=42; int *x; /* récupération de l'adresse d'une variable dans un pointeur */ x = &a; /* déréfencement et référencement ... */ a = 1 + *(&a);
/* toute valeur gauche peut etre referencee */ char buf[32]; char *s; /* s pointe sur le 5e caractere de buf */ s = &(buf[4]);
Exemple
Le classique des pointeurs: échange du contenu de deux variables.
#include <stdlib.h> #include <unistd.h> #include <stdio.h> /* swap(a,b) echange le contenu pointe par a et b */ void swap(int *a, int *b) { int c; c = *a; *a = *b; *b = c; } int main() { int x=0, y=42; printf("x=%d, y=%d\n",x,y); /* referencement de x et y pour etre utilises par swap */ swap(&x,&y); printf("x=%d, y=%d\n",x,y); return 0; }
Il y a deux points importants dans cette exemples:
- L'utilisation des pointeurs pour simuler un passage par référence (les paramètres globaux du langage algo.)
- Le réfencement des variables que l'on veut échanger lors de l'appel de la fonction swap.
Types
Les types de pointeurs sont identifiés par une étoile (*) après le type. Lors de la déclaration d'une variable de type pointeur (sur un entier par exemple) l'étoile sera syntaxiquement attachée à la variable et pas sur le type. Voici quelques exemples de déclaration:
/**** Tout separe: ****/ /* simple entier */ int x; /* pointeur sur entier */ int *y; /* tableau d'entiers (donc pointeur) */ int t[32]; /**** sur une ligne: ****/ int x, *y, t[32]; /**** dans un autre ordre ****/ int *y, x, t[32];
- Les trois blocs de déclarations sont tous équivalents.
Il est également possible d'utiliser la définition d'alias de types (typedef) pour cacher un type pointeur. On utilise ce genre d'alias lorsque la donnée abstraite à manipuler est directement représentée par le pointeur lui même (c'est le cas par exemple des listes chaînées ou des arbres.) Dans ce cas, le pointeur n'est pas visible dans la déclaration des variables.
Enfin, il existe un type de pointeur équivalent aux autres types de pointeur: void *. Ce type (qui n'a pas d'autre utilisation) pourra être utilisé un peu partout où l'on metterait un type pointeur. En règle générale, on ne peut pas vraiment déréfencer des pointeurs sur void.
L'exemple typique d'utilisation du type void * est la fonction de la libc malloc(3). Son prototype est:
void *malloc(size_t size);
Le type de retour est void *, et comme on peut le voir dans les exemples précédants (ou ceux du cours précédant) le résultat de malloc peut être utilisé avec n'importe quel type de pointeur.
On peut également utiliser le type void * pour transformer le type d'un pointeur dans un autre type. Bien évidement, ce genre de manipulation n'est pas conseillées. La fonction suivante est une fonction identité sur les pointeurs qui permet de changer le type d'un pointeur sans transtypage explicite:
#include <stdlib.h> #include <unistd.h> void *magic(void *x) { return x; } struct s_exemple { int a; int b; }; int main() { int x=0, y=0, *p; struct s_exemple *q; /* On recupere l'adresse de x */ p = &x; /* it's a kind of magic ... */ q = magic(p); q->b = 42; if (y) write(STDOUT_FILENO,"y a change\n",11); return 0; }
- Je vous laisse le plaisir de découvrir le résultat de ce programme ... (ne pas compiler avec l'option -O2.)
Tableaux
En C, les tableaux ne sont que des pointeurs. La syntaxe (comme vu dans le cours précédant) d'accès aux cases est un raccourcis sur l'arithmétique des pointeurs.
Le principe est simple, sur un tableau à une dimesion la case i du tableau t correspond au pointeur t + i. Techniquement, l'expression t[i] est complètement équivalente à *(t+i).
Cette approche à plusieurs impactes:
- Il n'y a aucun contrôle sur les dimensions des tableaux lors des accès.
- Il est possible d'utiliser des indexes négatifs.
- Les vrais tableaux à plusieurs dimensions sont (au moins partiellement) forcément statique.
Les 2 premiers points impliquent principalement plus de travail et de constration. Le dernier point est plus génant, on peut déclarer des tableaux à plusieurs dimensions de manière statique, mais il n'existe pas type pour décrire de tel tableau pour les prendre en argument (sauf à fixer la taille des différentes dimensions.)
En règle générale, on préférera utiliser des tableaux à une dimesion et on implantera le décalage à la main directement:
int get_matrix(size_t x, size_t y, int t[], size_t w) { return t[x + y * w]; }
Dans cette exemple, la fonction get_matrix(x,y,t,w) récupère la valeur de la case virtuelle t[x][y] (stocké en ligne d'abord.) Pour ça il nous faut la taille d'une ligne (w.) L'exemple montre que la connaissance de la taille des lignes est nécessaire et suffisante pour calculer le décalage, par conséquent, il possible de faire un tableau à deux dimensions partiellement dynamique:
#include <stdlib.h> #include <unistd.h> #include <stdio.h> /* Calcule la somme des cases d'une matrice de 32*h */ int sum_fixed_matrix(int t[][3], size_t h) { size_t i, j; int r = 0; for (j=0; j<h; j++) for (i=0; i<3; i++) r += t[j][i]; return r; } int main() { int t[4][3]; size_t x, y, i=0; /* remplissage du tableau */ for (y=0; y<4; y++) for (x=0; x<3; x++) t[y][x] = ++i; /* affichage */ for (y=0; y<4; y++) { for (x=0; x<3; x++) printf("%02d ",t[y][x]); printf("\n"); } printf("\nsum = %d\n\n",sum_fixed_matrix(t,4)); /* affichage lineaire */ for (x=0; x< 12; x++) printf("%02d ",((int *)t)[x]); printf("\n"); return 0; }
Arithmétiques des pointeurs
L'arithmétique des pointeurs est un peu particulière. En soi, la règle est simple: les opérations sur les pointeurs sont effectuées modulo la taille de la donnée pointée. Ce qui veut dire que si p est un pointeur sur entier, p + 2 correspond à l'adresse de p plus deux fois la taille d'un entier (et non pas plus deux octets.)
Par conséquent, l'équivalence syntaxique avec les tableaux est toujours vraie: *(t + i) est toujours équivalent à t[i].
Il est à noter qu'il n'est pas possible de faire de l'arithmétique sur des pointeurs de type void *, en effet quelle est la taille du vide ?
Allocation mémoire
Les données d'un programme peuvent se trouver dans deux endroits différents: le tas et la pile. La pile peut être considérée comme la zone de travail, elle est utilisée pour les variables locales, les paramètres de fonctions et les calculs intermédiaires. Le tas est l'espace non-organisé où le programme effectue ses allocations dynamiques.
Allocations statiques globales
Les données statiques (variables globales, constantes, chaînes constantes ... ) sont pré-allouées dans une troisième zone particulière.
Le cas particulier des chaînes constantes
Les constantes, de manière générale, sont décrites dans le binaire du programme et l'initialisation de celui-ci consiste entre autre à mettre ces valeurs à leur place en mémoire. Les chaînes de caractères représentent un problème différent: les chaînes constantes ne sont pas modifiables en mémoire. En effet, une chaîne étant normalement un pointeur sur une zone de caractère dont la taille n'est pas vérifiable, il faut garantir que les programmes ne vont pas y écrire en écrasant ce qui se trouve après.
Afin d'observer comment sont sauvées les chaînes, voici le code assembleur générer pour le fichier C suivant:
/* foo.c */ char *s = "a string";
.file "foo.c" .section .rodata .LC0: .string "a string" .globl s .data .p2align 2 .type s, @object .size s, 4 s: .long .LC0 .ident "GCC: (GNU) 3.4.6 [FreeBSD] 20060305"
On voit apparaître clairement notre chaîne de caractères en dure dans le code assembleur. C'est le cas pour toutes les chaînes écrites explicitement sous la forme "chaine". Sans option de compilation particulière, ces chaînes sont toujours constantes et ne peuvent être utilisées dans un contexte où elles seront modifiées.
/* ex-str.c */ int main() { char *s = "chaine"; s[0] = 'C'; return 0; }
Ce code passera la compilation (le compilateur ne peut détecter le fait que vous accédier à zone mémoire qui sera en lecture seule à l'exécution), mais il échouera à l'exécution.
un_shell> gcc -W -Wall -Werror -pedantic -ansi -o ex-str ex-str.c un_shell> ./ex-str Segmentation fault un_shell>
Si vous désirez voir le code assembleur généré pour du code C, il suffit d'appeler gcc avec l'option -S:
> ls foo.c > gcc -S foo.c > ls foo.c fooc.s
Déclaration des constantes
Outre les chaines constantes, il est possible de déclarer d'utiliser des constantes dans un programme. Le terme de constante s'applique en réalité à beaucoup de chose: valeurs immédiates, macros, variables globales jamais modifiées, déclarations statiques de certaines valeurs ...
Macros
Il est possible de nommer des valeurs immédiates pour l'ensemble du programme sans passer par des variables globales. Ces macros sont remplacées par le pré-processeur avant le passage du compilateur. Voici la syntaxe:
#define CTE valeur
Dans la suite du programme, toutes les occurences de CTE seront remplacées par valeur.
Attention: le remplacement des macros est fait systématiquement, par conséquent, il vaut mieux s'assurer qu'aucun identifiant ne porte le même nom dans le code, sous peine d'erreurs étranges.
Tableaux et structures immédiates
Il est possible de déclarer le contenu d'un tableau (ou d'une structure) à l'aide de la syntaxe suivante:
int tab[5] = {0,1,2,3,4};
L'expression entre accolade ({}) servira à remplir la zone mémoire du tableau (les valeurs correspondant à chaque sous-expression seront collée en mémoire les une à la suite des autres.) La même syntaxe s'applique pour les structures.
On notera que les deux chaînes suivantes ne sont pas équivalentes:
char *s1 = "bonjour"; char s2[8] = {'b','o','n','j','o','u','r',0};
Il est possible d'écrire dans la chaîne s2 mais pas dans s1.
Enfin, la taille du tableau ainsi déclaré est facultative, le compilateur peut la déduire de lui même:
#include <stdlib.h> #include <unistd.h> #include <stdio.h> int main() { char s[] = {'H','e','l','l','o',0}; printf("s[%u] = \"%s\"\n",sizeof (s), s); return 0; }
Un exemple avec une structure:
struct s_contact { char *nom, *prenom, *mail; size_t age; }; struct s_contact moi = {"Burelle","Marwan","marwan[AT]lse.epita.fr",32};
Code assembleur généré
Voici un petit exemple de programme avec quelques déclarations (et quelques affichages à titre d'exemple):
/* constantes.c */ #define CTE 1 #include <unistd.h> #include <stdlib.h> #include <stdio.h> struct s_ex { int a; char c; }; struct s_ex s = { 1, 'a' }; int tab[5] = {4,3,2,1,0}; char str[8] = {'b','o','n','j','o','u','r',0}; int main() { int i; for (i=0; i<5; i++) printf("tab[%d] = %d\n",i,tab[i]); printf("s = { a = %d; c = '%c'}\n",s.a,s.c); printf("tab = 0x%x\n&s = 0x%x\n&i = 0x%x\n", (int)tab, (int)&s, (int)&i); return(0); }
Le code assembleur généré pour ce programme sera:
.file "constantes.c" .globl s .data .p2align 2 .type s, @object .size s, 8 s: .long 1 .byte 97 .zero 3 .globl tab .p2align 2 .type tab, @object .size tab, 20 tab: .long 4 .long 3 .long 2 .long 1 .long 0 .globl str .type str, @object .size str, 8 str: .byte 98 .byte 111 .byte 110 .byte 106 .byte 111 .byte 117 .byte 114 .byte 0 .section .rodata .LC0: .string "tab[%d] = %d\n" .LC1: .string "s = { a = %d; c = '%c'}\n" .p2align 2 .LC2: .string "tab = 0x%x\n&s = 0x%x\n&i = 0x%x\n" .text .p2align 2,,3 .globl main .type main, @function main: pushl %ebp movl %esp, %ebp subl $8, %esp andl $-16, %esp movl $0, %eax addl $15, %eax addl $15, %eax shrl $4, %eax sall $4, %eax subl %eax, %esp movl $0, -4(%ebp) .L2: cmpl $4, -4(%ebp) jg .L3 subl $4, %esp movl -4(%ebp), %eax pushl tab(,%eax,4) pushl -4(%ebp) pushl $.LC0 call printf addl $16, %esp leal -4(%ebp), %eax incl (%eax) jmp .L2 .L3: subl $4, %esp movsbl s+4,%eax pushl %eax pushl s pushl $.LC1 call printf addl $16, %esp leal -4(%ebp), %eax pushl %eax pushl $s pushl $tab pushl $.LC2 call printf addl $16, %esp movl $0, %eax leave ret .size main, .-main .ident "GCC: (GNU) 3.4.6 [FreeBSD] 20060305"
Allocations statiques sur la pile
La pile d'appels est structurée comme une pile classique, on dispose d'un pointeur de pile (indiquant le sommet de celle-ci) ainsi que d'un pointeur de cadre indiquant le début de la pile pour le contexte courant.
La pile permet d'organiser les variables lors des appels de fonctions. Le contexte de la fonction (paramètres, variables, adresse de retour, ancien pointeur de cadre ... ) est positionné sur la pile, puis lorsque la fonction se termine, son contexte est retiré de la pile pour revenir dans l'état d'avant l'appel.
Par conséquent, la mémoire allouée sur la pile sera perdue (en fait, réutilisée) dès que la fonction courante se termine. Les blocs de mémoire sur la pile sont éphémères et l'on ne doit jamais renvoyer un pointeur sur une donnée de la pile.
Par exemple, la fonction suivante risque de poser problème, vu que x n'existe plus après la sortie de la fonction:
int *f() { int x = 1; return (&x); }
Allouer un zone mémoire d'une taille particulière sur la pile
Lorsque l'on désire déclarer une zone mémoire dont la taille est déterminée statiquement et que la durée de vie de cette zone ne dépassera pas le contexte courrant, on peut utiliser la déclaration des tableaux statiques:
int tab[5];
Dans l'exemple, une zone mémoire pouvant contenir 5 entiers (donc de taille 5 * sizeof (int), soit 20 octets en 32bits) sera allouée sur la pile. tab pointera alors sur cette zone (en pratique, le pointeur n'existe pas, le compilateur remplacera les appels à l'adresse tab par son adresse, donc dans ce cas tab == &tab.)
La zone mémoire étant sur la pile sa durée de vie est la même que celle du contexte courrant.
Structure et pile
Lorsque l'on manipule des structures et surtout des pointeurs sur structure, on est en général amené à allouer explicitement la taille de la structure (avec malloc(3)) comme dans l'exemple suivant (ajout d'un élément en tête d'une liste chaînée):
typedef struct s_list *t_list; struct s_list { int data; t_list next; }; t_list add(int x, t_list l) { t_list *tmp; tmp = malloc(sizeof (struct s_list)); tmp->data = x; tmp->next = l; return tmp; }
Lorsque la durée de vie de la structure manipulée ne dépasse pas la durée de vie du contexte courant, il peut être pratique d'utiliser une structure immédiate sur la pile.
Dans l'exemple suivant, on va utiliser la structure de liste de l'exemple précédant, mais l'on va créer une sentinelle insérée à une position particulière de la liste pour arrêter le parcours effectué après (noté que cet exemple, en l'état est complètement inutil):
void iterations(t_list l, int bound) { t_list tmp, save_pos; struct s_list sentinel; sentinel.data = -42; for (tmp=l; tmp && tmp->data != bound; tmp = tmp->next) ; if (tmp) { save_pos = tmp; sentinel.next = tmp->next; tmp->next = &sentinel; for (tmp=l; tmp && tmp != &sentinel ; tmp = tmp->next) printf("%d;",tmp->data); save_pos->next = sentinel.next; } }
On commence par rechercher une position particulière de la liste (l'entier bound passé en paramètre), lorsque l'on trouve celle-ci, on sauve la position et l'on remplace le maillon suivant de la chaîne par notre sentinelle locale (notée l'utilisation du référencement pour obtenir l'adresse.) Enfin, on parcours la liste (en affichant chaqu'un des maillons) et on s'arrête lorsque l'on rencontre la sentinelle (on notera ici l'usage de l'adresse de la sentinelle comme borne pour notre itération.) Bien évidement, on restaure l'état de la liste originale avant de terminer.
Allocations dynamiques
Lorsque l'on a besoin de zones mémoires dynamiques dont la durée de vie est supérieure à celle d'une variable locale, nous allons utiliser le tas. La méthode la plus simple est d'utiliser l'allocateur fourni par la libc: malloc(3).
Cet allocateur fournit quatre fonctions:
- malloc qui alloue une taille donnée sur le tas
- calloc qui alloue un tableau dont le nombre et la taille des cases est en paramètre (les cases sont initialisés à zéro.)
- realloc qui permet de redimmensionner un zone précédemment obtenue avec l'une des trois fonctions d'allocations.
- free qui libère une zone mémoire allouer avec l'une des trois autres fonctions.
Les prototypes sont les suivants:
#include <stdlib.h> void *malloc(size_t size); void *calloc(size_t number, size_t size); void *realloc(void *ptr, size_t size); void free(void *ptr);
La logique est la même pour les trois opérations d'allocations:
- si la place demandée est disponible, la fonction renvoie un pointeur sur une zone réservée de la bonne taille. Il n'y a aucune intersection entre cette zone et les autres zones allouées.
- si la place n'est pas disponible, la fonction renvoie le pointeur NULL.
La fonction calloc(number,size) renvoie une zone de taille number * size remplie de zéro.
La fonction realloc(ptr,size) essaie de réutiliser la zone pointée par ptr (si le changement de taille n'est pas important), sinon il alloue un nouveau bloc et y copie le contenu de l'original qui sera ensuite libérer par free.
#include <stdlib.h> #include <unistd.h> #include <stdio.h> int main() { void *p1, *p2; p1 = malloc(32); p2 = realloc(p1, 256); printf("p1 = %p\np2 = %p\n",p1,p2); return 0; }
La sortie de ce programme nous montre que le pointeur n'est pas forcément le même:
> gcc -O2 -W -Wall -Werror -ansi -pedantic real.c -o real > ./real p1 = 0x28201020 p2 = 0x28202100
Un usage classique de realloc concerne les vecteurs de taille dynamique:
typedef struct s_vect *t_vect; struct s_vect { size_t last, size; int *tab; }; t_vect new_vect() { t_vect v; v = malloc(sizeof (struct s_vect)); v->last = 0; v->size = 1; v->tab = malloc(sizeof (int)); return v; } void add(int x, t_vect v) { if (v->last >= v->size) { /* size = size * 2 */ v->size <<= 1; v->tab = realloc(v->tab, v->size * sizeof (int)); } v->tab[v->last++] = x; }
Normalement, les adresses renvoyés par malloc et ses amis sont alignées sur la taille d'un entier (4 octets en 32bits.)
#include <stdlib.h> #include <unistd.h> #include <stdio.h> int main() { printf("%u\n",((size_t)malloc(17)) % sizeof (int)); return 0; }
Ce programme affichera normalement toujours 0.
Structure et organisation de la mémoire
- La lecture de cette partie du cours et de la suivante, peut être complétée par la lecture de mon tutorial sur malloc(3) (en pdf et en anglais.)
Sur un système multitâche, la mémoire manipulée par nos programmes doit être partagées entre les différents processus en cours d'exécution. Ce partage pose plusieurs problèmes:
- La localisation du processus en mémoire et par conséquent l'usage d'adresse absolue.
- L'espace mémoire attribué à chaque processus et son évolution en cours d'exécution.
- La continuité de la mémoire d'un processus.
- Le confinement de la mémoire d'un processus et donc son intégrité.
Mémoire virtuelle et pagination
Principe général
Sur les processeurs récents, il existe une entité chargée de la gestion de la mémoire appelée MMU (Memory Management Unit.) Le rôle de la MMU est d'assurer la traduction, à la volée, des adresses manipulées par les programmes en adresses sur la mémoire physique. C'est ce qu'on appelle la mémoire virtuelle.
Cette solution répond à tous les problèmes que nous avons évoqués: comme les adresses sont traduites à la volée, il est possible d'organiser la mémoire d'un processus selon un schéma toujours identique et donc de permettre à celui-ci d'utiliser un adressage absolue. De même, l'organisation de la mémoire virtuelle permet de placer les éléments dont la taille peut varier au cours de l'exécution de manière à ce que ceux-ci est toujours la place de grandir. Ainsi, la pile du programme sera en générale placée à la fin de la mémoire et grandira en sens inverse de la mémoire (le sommet de la pile se trouve à une adresse plus petite que la base de la pile.)
L'espace alloué à un processus évoluera de même, en fonction de ses besoins (et de la mémoire physique effectivement disponible), en ajoutant des entrées dans la table de traductions de la MMU. L'espace mémoire ainsi obtenu parraitra toujours continue au programme même si ce n'est pas la cas en mémoire physique.
Enfin, le problème du confinement est directement réglé en excluant des traductions pour un processus les zones mémoires qui ne lui appartiennent pas. Ainsi, aucun processus ne peut, quoi qu'il fasse, accéder à la mémoire des autres processus.
Pagination
Pour pouvoir traduire les adresses virtuelles en adresses physiques, la MMU doit disposer d'un table de traduction. Cette table associera à chaque adresse virtuelle l'adresse physique correspondante. Seulement, si la traduction est effectuée adresse par adresse, il y a un petit problème de taille.
Prennons l'exemple d'un système 32bits:
- les adresses sont codées sur 4 octets (32 bits)
- il y a donc
adresses possibles (donc 4 Go)
- il nous faut donc une table de
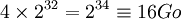
Il est donc impossible d'assurer la traduction adresse par adresse de la mémoire. Par contre, on peut travailler avec une mémoire découpée en bloc, c'est la pagination.
La mémoire virtuelle et la mémoire physique sont donc découpées en blocs (en général de taille constante) que l'on appelle pages pour la mémoire virtuelle et cadres pour la mémoire physique. La table de traduction ne contient donc plus que le nombre d'entrées nécessaires pour le nombre de pages à traduire et la taille des entrées est également plus petite.
En règle générale, la taille des pages est de 4ko. Il faut donc 12bits pour représenter la position dans la page (on utilisera pour ça les 12 bits de poids faibles de l'adresse) et il reste donc 20bits (en 32bits) pour le numéro de la page. La taille de la table reste importante (de l'ordre de 2 ou 3 Mo) mais est bien plus raisonnable.
Pour améliorer et simplifier le chargement de la table de traduction, cette table est découpée hiérarchiquement sous la forme d'un arbre général de recherche (similaire à un arbre B+): les adresses de pages sont regroupées par intervalles sur plusieurs niveaux. On s'arrange en générale pour que chaque sous-tables (chaque nœud) de cette hiérarchie tienne sur une page !
Le break (brk(2) et sbrk(2))
La mémoire d'un processus est composée de différentes parties, la taille, la position et la nature de ces parties peut varier en fonction des architectures, des systèmes et même des programmes. Mais il y a quelques constantes, l'espace d'adressage sera donc découpé en respectant la logique suivante:
- une zone pour le code, en général tout en haut de la mémoire.
- une zone pour les données statiques et constantes, en général juste après le code.
- une zone pour les allocations dynamiques, le tas, en général après les données statiques.
- une zone pour la pile, en général en fin de mémoire.
Le tas est la zone la plus dynamique de la mémoire d'un programme. Sa limite est marquée par le break: la frontière entre les adresses virtuelles ayant une traduction en adresses physiques et celles qui ne sont pas traduites. Le premier rôle d'un allocateur de mémoire et de contrôler le break en fonction des besoins du programme.
La norme POSIX (SUSv1 et SUSv2, le statut actuel de ces deux appels système est ambigüe: ils ont été normalement retirés de la norme, mais sont nécessaires à l'implantation d'un allocateur simple et sont donc toujours disponible dans la libc des systèmes UNIX) nous fournit deux opérations pour ça:
#include <unistd.h> int brk (void *addr); void *sbrk (int increment);
- brk(addr) positionne le break à l'adresse addr si possible et renvoie 0 en cas de succès et -1 sinon.
- sbrk(increment) ajoute increment au break allouant (si increment est positif) la quantité de mémoire correspondate ou désallouant cette quantité (sinon ... ) sbrk renvoie l'ancienne adresse du break (ce qui n'a pas toujours été le cas sur certains systèmes ... )
Initialement, ces deux appels systèmes étaient utilisés pour obtenir de la mémoire, mais leur usage a été rendu obsolette par malloc(3) qui fournit une interface de plus haut niveau pour l'allocation mémoire. Sur beaucoup de systèmes, malloc(3) utilise brk(2) et sbrk(2), il est donc fortement déconseillé de mélanger l'usage de ces opérations.
Voici, un exemple de malloc minimaliste utilisant sbrk:
#include <unistd.h> #include <stdlib.h> void *my_malloc(size_t s) { void *p; p = sbrk(0); if (sbrk(s) == (void *) -1) p = NULL; return p; }
Si on est sûr que sbrk(2) renvoie l'ancienne adresse du break, on peut même simplifier un peu le code:
void * my_malloc(size_t s) { void *p; return ((p = sbrk(s)) == (void*) -1? NULL : p); }
mmap(2)
L'appel système mmap(2) sert normalement à associer une zone mémoire à un file descriptor. Mais il est aussi possible de l'utiliser en mode anonyme pour allouer des pages mémoires. Son prototype est le suivant:
#include <sys/mman.h> void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
- addr: si possible mmap(2) placera les pages allouées à proximité de ce pointeur, mais sans aucune garantie. Ce paramètre peut être NULL
- length: correspond à la taille à allouer.
- prot: mode d'accès à la page
- flags: contrôle des différentes options
- fd: le file descriptor associé
- offset: le décalage dans la fichier d'origine, doit obligatoirement être aligné sur la taille d'une page.
Pour obtenir l'allocation d'une zone mémoire dans le même esprit que malloc(3), l'appel devra ressembler à:
void *p; p = mmap(NULL, s, PROT_READ|PROT_WRITE, MAP_ANON, -1, 0);
Pour libérer la mémoire ainsi allouée, il suffit d'utiliser l'appel mémoire munmap(2):
int munmap(void *addr, size_t length);
mmap(2) travaille avec des pages, par conséquent, toute demande de mémoire sera arrondie au multiple de la taille d'une page immédiatement supérieur. Il est donc recommandé de n'utiliser mmap(2) que pour de grosses allocations.
Contrairement à brk(2) et sbrk(2), mmap(2) peut très bien s'utiliser conjointement avec malloc(3).
On peut aussi utiliser mmap(3) pour autre chose que de simples allocations mémoires (chargement sans lecture de fichier, partage de zone mémoire avec d'autre processus ... )
Fonctionnement de malloc(3)
Pour des raisons de place cette section est sur une page séparée:
Autres techniques pour la gestion de la mémoire
Même si dans la programmation de tous les jours, on réécrit rarement un allocateur mémoire, il est possible d'utiliser des techniques spécifiques pour répondre à des besoins particuliers.
En C il n'existe pas vraiment d'outils standards autre que malloc(3) pour la gestion de la mémoire (si ce n'est les opérations bas niveaux comme sbrk(2) et mmap(2).) Il est donc intéressant de regarder ces techniques.
Basiquement, ces techniques s'appuient sur les même principes que malloc avec des aspects particuliers en plus.
Pools de recyclage
Lorsque l'on manipule des structures chaînées on est souvent amené à allouer/libérer des séries de petits blocs, tous identiques. Il peut donc être intéressant de réutiliser les mêmes blocs. La stratégie classique suit le schéma suivant:
- Allocation d'un gros tableau de blocs (le pool.)
- Chaque allocation consiste à sélectionner une cas non utilisée dans le tableau
- À la libération, il suffit de marquer le bloc comme libres.
- Potentiellement, on peut agrandir le pool (mais pas avec realloc(3) !)
Comme les blocs sont tous de même taille et qu'ils ont déjà une certaine structure, il est très simple de mettre en place un algorithme de sélection relativement peut coûteux.
Allocations par vague (memory pools)
Dans le même esprit que les pools de recyclage, il peut être intéressant de libérer un ensemble de pointeurs en une fois. Pour comprendre cette logique, il faut faire un parallèle avec la notion de variables locales: dans une fonction les variables manipulées vont toutes être créée au début de la fonction et seront toutes détruites à la sortie de la fonction. Cette logique se propage sur les phases d'activités d'un programme: lorsque le programme commence une nouvelle phase il va mettre en place un certain nombre de blocs mémoires et lorsque cette phase se termine, il faut libérer ces blocs.
Pour mettre en place ce type de techniques, on suit un peu la même logique que précédement:
- On alloue un gros bloc qui servira de tas temporaire (le pool.)
- Toutes les allocations se font dans le pool avec un allocateur spécifique.
- Lorsque l'on désire libérer l'ensemble des allocations, on libère le pool.
En partant du principe qu'il n'est pas nécessaire d'implanter une opération de libération des petits blocs, on peut utiliser un allocateur basique qui se contente d'avancer la fin du pool. On peut aussi spécialiser l'allocateur lorsque l'on maîtrise la taille des allocations concernées.
| Cours | Partie |
|---|---|
| Cours de Programmation EPITA/spé | Programmation:C |